構造体-データをまとめて管理する
大量のデータをまとめて扱う時に便利なものとして配列を説明してきました。配列は「10人の身長」や「100人の10科目の点数」といったデータをまとめて扱う時に、繰り返し処理と組み合わせて利用して便利さを発揮するものでした。つまり、「整数」や「実数」や「文字」といった同種類のデータが膨大にあり、それらを1つにまとめて扱いたいときに配列を使ってきました。次のようなデータを扱うときを考えてみましょう。
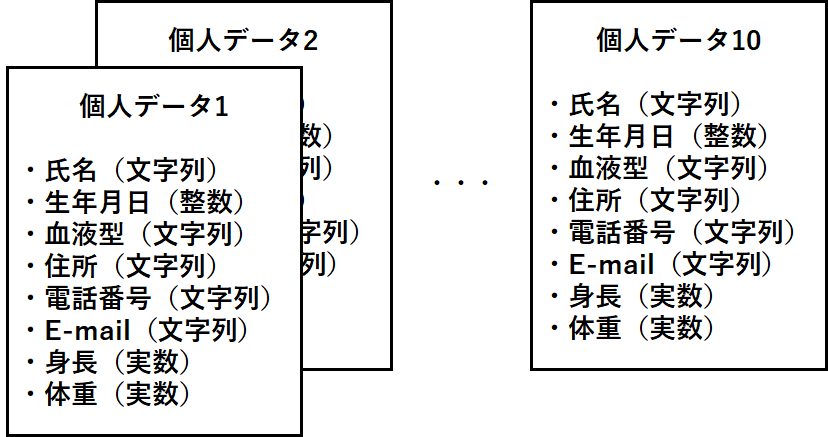
このようなデータを配列で扱う場合は、
1人の氏名の文字型1次元配列×10 → 文字型2次元配列 1人の生年月日の整数型変数 ×10 → 整数型1次元配列 1人の体重の実数型変数 ×10 → 実数型1次元配列
というように個々のデータをまとめて管理できます。しかし、サンプルデータの図のように個人のデータを一つにまとめられません。配列は同じ型のデータのみをまとめて扱う方法だからです。このようなデータをまとめるときに用いるのが構造体(structure type)です。
実際にデータをまとめてプログラミング
実際に大きなプログラムを作る時は、大人数で分割して作っていきます。そのため、どのようなプログラムを作るか決めたら、データをどう扱うかというとデータ構造(data structure)をまず決めなければあとでつじつまが合わなくなります。
まずは、最も基本的な構造体について例題を見ながら、考えていきましょう。
例題:A君とB君のデータとして次の表があります。それぞれの項目名を選択し入力すると、二人のデータが同じか異なっているかを判定し、結果を表示するプログラムを作成します。
| 項目 | A君 | B君 |
| 血液型 | A | B |
| 出身地 | 長野 | 長野 |
| 年齢 | 21 | 22 |
| アルバイト経験(月) | 15 | 12 |
| 時給(円) | 800 | 800 |
このプログラムを作るにあたり、データをどのように変数に格納するかデータ構造を考えます。まず、1人分のそれぞれの項目にどの型を使いどれだけの大きさが必要になるかまとめると以下のようになります。
| 血液型 | 文字型(1文字) |
| 出身地 | 文字型(5文字) |
| 年齢 | 整数型 |
| アルバイト経験(月) | 整数型 |
| 時給(円) | 整数型 |
ここで血液型はAB型がないので、1文字、出身地は全角2文字なので、その倍の「4文字+何もない文字\0」で5文字として準備します。
- 二人分のデータなので、A君を0番、B君を1番とした配列で準備するとします。
| 血液型 | char blood[2] |
| 出身地 | char area[2][5] |
| 年齢 | int old[2] |
| アルバイト経験(月) | int exp[2] |
| 時給(円) | int wage[2] |
このようにするとデータをまとめることが出来ますが、普段考える時にはA君のデータを1つのグループ、B君のデータを1つのグループと考える事は多いのではないでしょうか?
- A君をAdata、B君をBdataというデータで表すとします。
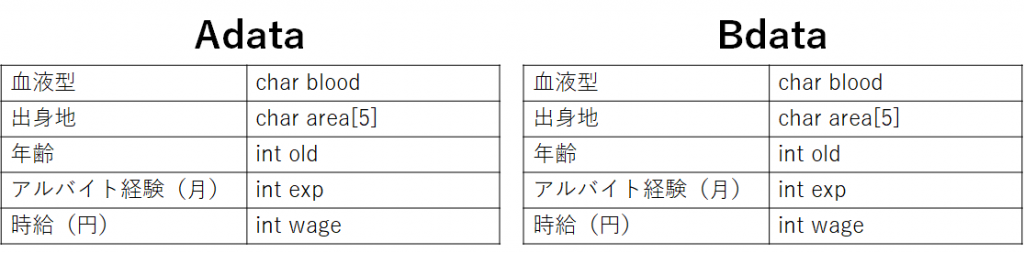
こちらのデータ表現の方がしっくりくると思います。構造体を使うことにより、データのまとまりを作ることが出来ます。
次にこの例題のアルゴリズムを考えます。
- A君のデータを既定値で初期化する
- B君のデータを既定値で初期化する
- どの項目を比較するかを数値で入力できるように、「何で比較しますか? 1:血液型 2:出身地 3:年齢 4:アルバイト経験 5:時給」という質問を表示する
- 入力された項目でA君とB君のデータを比較し、同じならば「二人は同じです」、異なれば「二人は違います」と表示する
ソースプログラムは以下のように記述します。
#include <stdio.h>
#include <string.h>
struct private_data{ //①
char blood;
char area[5];
int old, exp, wage;
};
int main(){
struct private_data Adata, Bdata; //②
int input;
int same;
/*③A君の既定データの代入*/
Adata.blood = 'A';
strcpy(Adata.area, "長野");
Adata.old = 21;
Adata.exp = 15;
Adata.wage = 800;
/*③B君の既定データの代入*/
Bdata.blood = 'B';
strcpy(Bdata.area, "長野");
Bdata.old = 22;
Bdata.exp = 12;
Bdata.wage = 800;
/*質問の表示と選択結果の入力*/
printf("何で比較しますか?\n");
printf("1:血液型 2:出身地 3:年齢 4:アルバイト経験 5:時給\n");
scanf("%d", &input);
same = 0;
/*判定と結果表示*/
switch(input){
case 1:if(Adata.blood == Bdata.blood) same = 1;
break;
case 2:if(strcmp(Adata.area, Bdata.area) == 0) same = 1;
break;
case 3:if(Adata.old == Bdata.old) same = 1;
break;
case 4:if(Adata.exp == Bdata.exp) same = 1;
break;
case 5:if(Adata.wage == Bdata.wage) same = 1;
break;
default:printf("そんな項目番号はありません\n"); same = 2;
break;
}
if(same == 0){
printf("二人は違います\n");
}else{
if(same == 1){
printf("二人は同じです\n");
}
}
return(0);
}①どんな構造体かを記述する
この部分は、構造体がどんな変数のまとまりなのかを定義している部分です。構造体は、複数の変数をまとめて1つの名前で管理します。struct(ストラクト)のあとに、「何という名前の構造体であるか」、その中にまとめて扱うのは「どんな変数で何という名前なのか(変数の宣言)」を記述します。最後に「;」がついてることにも注意しましょう。
■構造体の定義
struct 定義する構造体の名前
{
変数の型 変数名(配列名[])
};
ただし、ここでは、private_dataがどんなデータを扱うのか、その型を定義しているだけであって、構造体の実体を作っているわけではありません。
②構造体を使った変数宣言
この部分での記述は、①で決めた構造体の名前を使って、実際に構造体のデータを記憶する場所を用意しています。この記述を構造体を使った変数宣言といいます。
■構造体の変数宣言 struct [構造体の名前] [実際に利用する変数名] struct private_data Adata, Bdata;
③構造体でまとめたそれぞれの変数に値を代入
これらの記述は、構造体でまとめたそれぞれのデータに対して、値の代入や、値の参照を行っています。以下のようなAdataのまとまりの中にある変数bloodに値を代入する時は、「Adata.blood = [値]」のようにしてピリオド(.)をつけて記述します。

「Adataのまとまりの中のblood」→ Adata.bloodのように「.」を「~のまとまりの中の」と読み替えるとわかりやすいでしょう。
構造体と配列の利用
「構造体=いくつかの変数をまとめて扱うもの」というイメージができてると思います。しかし、上のような例では構造体を使ってもプログラムの記述が複雑になるだけで、構造体でまとめるメリットをなかなか感じられないと思います。構造体と配列を両方利用してはじめてメリットを感じ取れるはずです。
次の例題で考えていきましょう。
例題:50人の個人データが記述されているテキストファイルがある。このとき、年齢・月収の項目について、データの分布を調べ、グラフにまとめる。

- データ構成を考える
まずは、データをどのように表現するかというデータ構造を考えてみましょう。この問題では、「名前」「年齢」「誕生月」「郵便番号」「月収」の5つのデータが1人のデータとしてあるので、これを構造体としてまとめると以下のようになります。
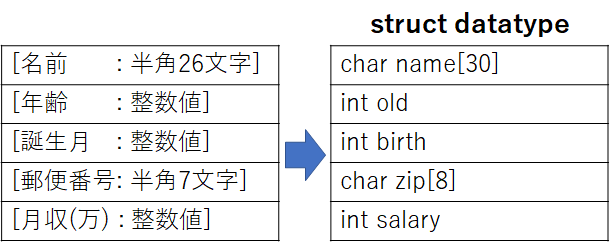
さらに、この問題では、50人分のデータを取り扱うため、この構造体を50個まとめた1次元配列で表します。そのため、構造体の配列を準備する変数宣言は、先のdatatypeの構造定義を利用して次のように記述できます。
struct datatype data[50];
構造体の配列で「struct 構造定義名 配列名 [n][m]…」と書きます。この構造体の配列で、0番目のデータである名前を扱う時は「data[0].name」といった形で記述します。
これらを含め、プログラムにすると次のように記述できます。
#include <stdio.h>
#include <string.h>
struct datatype{
char name[30];
int old, birth;
char zip[8];
int salary;
};
/*graph[]の内容をグラフ表示する関数*/
int write_graph(int graph[5]){
int i, j;
/*軸の表示*/
printf("-----|");
for(i=0; i<5; i++){
for(j=0; j<9; j++)
printf("-");
printf("+");
}
printf("\n");
/*ヒストグラム・グラフの表示*/
for(i=0; i<5; i++){
if(i!=4)
printf("%2d-%2d|", i*2*10, (i*2+2)*10);
else
printf("80---|");
for(j=0; j<graph[i]; j++)
printf("*");
printf("\n");
}
/*軸の表示*/
printf("-----|");
for(i=0; i<5; i++){
for(j=0; j<9; j++)
printf("-");
printf("+");
}
printf("\n");
return(0);
}
int main(){
struct datatype data[50];
FILE *FP;
int graph[5];
int i;
/*ファイルの読み込みモードでのオープン*/
if((FP=fopen("personal_data.txt", "r"))==NULL){
printf("ファイルが開けません\n");
return(1);
}
/*ファイルからデータを読み込む*/
for(i=0; i<50; i++){
/*nameの読み込み*/
fgets(data[i].name, 29, FP);
data[i].name[strlen(data[i].name)-1]='\0';
/*oldの読み込み*/
fscanf(FP, "%d\n", &data[i].old);
/*birthの読み込み*/
fscanf(FP, "%d\n", &data[i].birth);
/*zipの読み込み*/
fgets(data[i].zip, 8, FP);
data[i].zip[7]='\0';
/*salaryの読み込み*/
fscanf(FP, "%d\n", &data[i].salary);
}
/*graphの初期化*/
for(i=0; i<5; i++){
graph[i]=0;
}
/*oldの集計*/
for(i=0; i<50; i++){
if(data[i].old>=0){
if(data[i].old<20){
graph[0]=graph[0]+1;
}else{
if(data[i].old<40){
graph[1]=graph[1]+1;
}else{
if (data[i].old<60){
graph[2]=graph[2]+1;
}else{
if(data[3].old=graph[3]+1){
graph[3]=graph[3]+1;
}else{
graph[4]=graph[4]+1;
}
}
}
}
}
}
/*graph[]をグラフ化して表示*/
printf("\n年齢分布\n");
write_graph(graph);
/*グラフの初期化*/
for(i=0; i<5; i++){
graph[i]=0;
}
/*salaryの集計*/
for(i=0; i<50; i++){
if(data[i].salary>=0){
if(data[i].salary<20){
graph[0]=graph[0]+1;
}else{
if(data[i].salary<40){
graph[1]=graph[1]+1;
}else{
if (data[i].salary<60){
graph[2]=graph[2]+1;
}else{
if(data[3].salary=graph[3]+1){
graph[3]=graph[3]+1;
}else{
graph[4]=graph[4]+1;
}
}
}
}
}
}
/*graph[]をグラフ化して表示*/
printf("\n年齢分布\n");
write_graph(graph);
return(0);
}これまでよりソースプログラムのサイズは大きくなりますが、まとまりごとに慎重に見れば、理解できるでしょう。
構造体の基本的な使い方は以上ですが、「構造体の基本は簡単でもどう使うかが勝負」です。センスの悪い構造体を作ってもプログラムが見づらくなるだけです。プログラムを書きながら、適切な使い道を模索していきましょう。